Super Mario Bros 3 AI
A reinforcement-learning agent trained with PPO and curriculum learning to play Super Mario Bros 3 from raw pixels, with difficulty that scales as it improves.
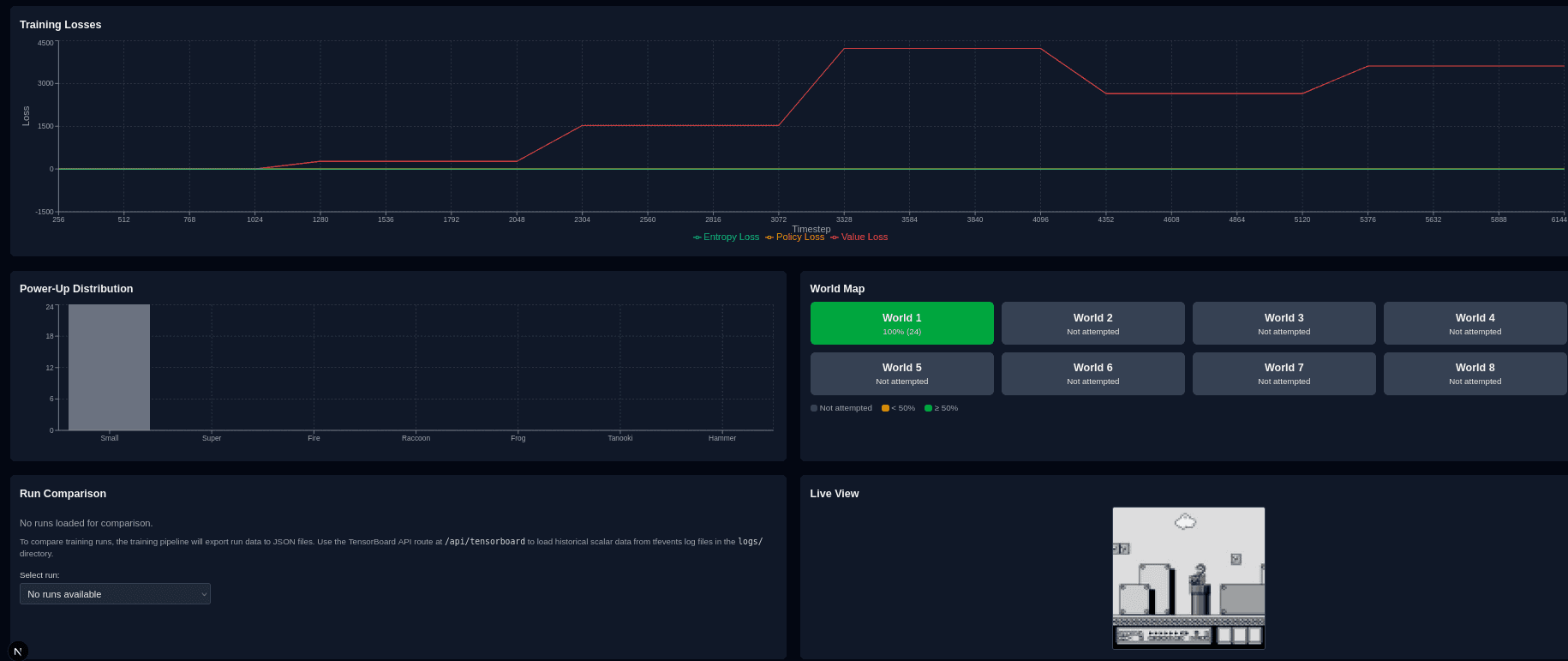
About the project
An in-progress project training an AI agent to complete levels of Super Mario Bros 3 with Proximal Policy Optimization (PPO). The agent learns from raw pixels through a convolutional network, and a curriculum progressively unlocks harder worlds as it hits performance thresholds.
The goal
Train a reinforcement-learning agent to clear levels of Super Mario Bros 3 using modern RL. Along the way it's a sandbox for exploring reward shaping, curriculum learning, and the realities of learning from raw pixels in a busy game environment.
The approach
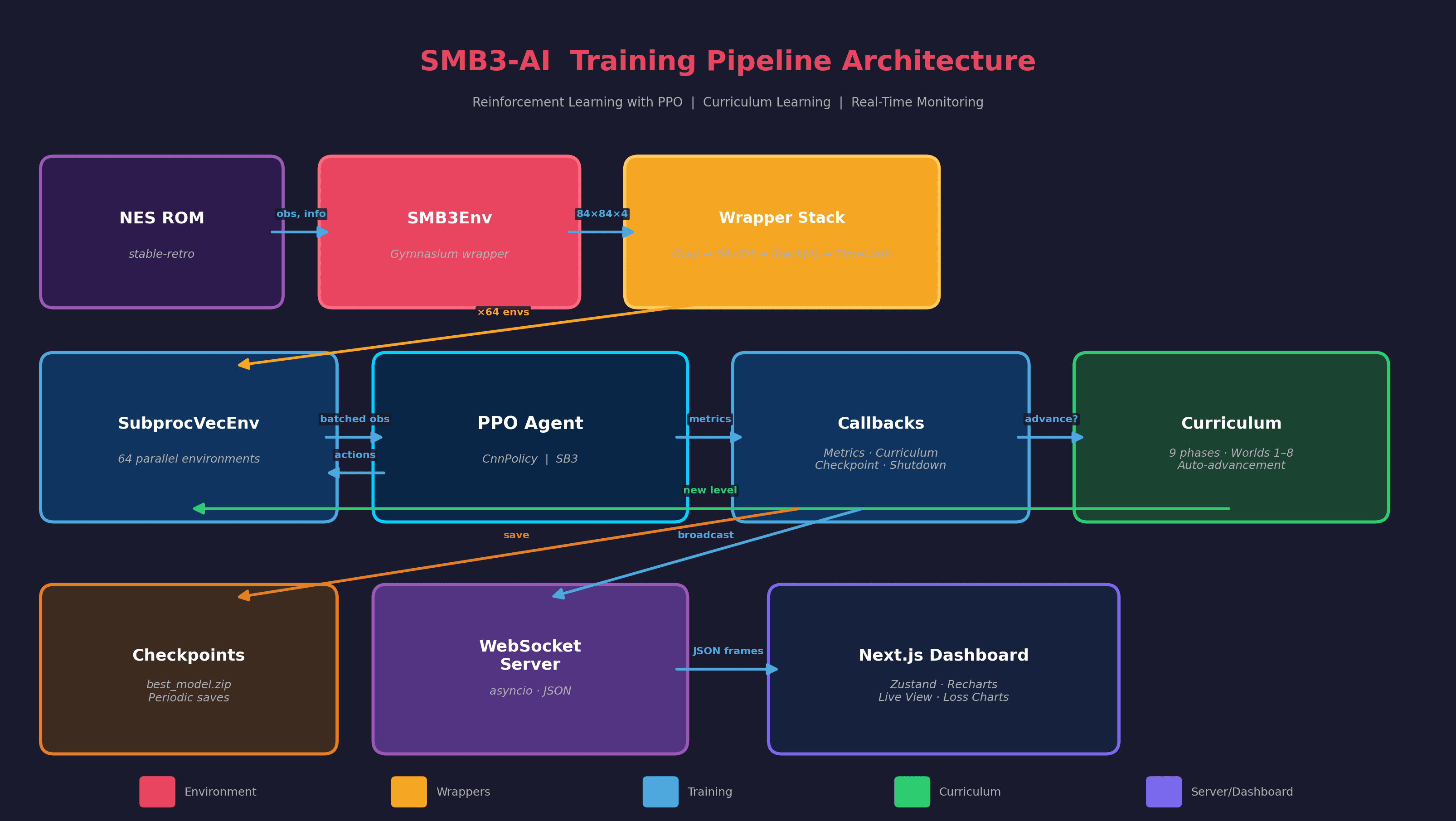
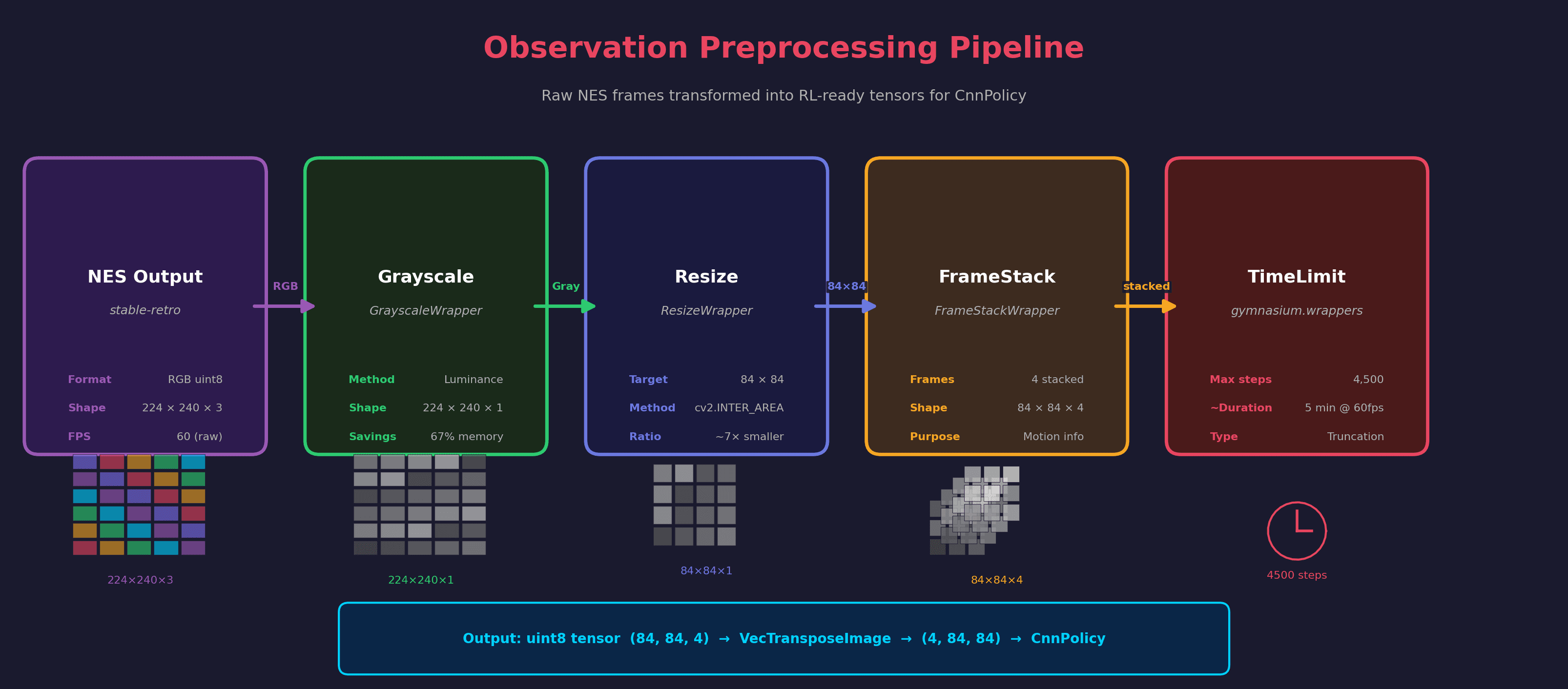
The agent uses PPO with a convolutional policy that reads raw pixels — 84×84 grayscale frames stacked four deep to capture motion. Training runs across many parallel environments via SubprocVecEnv for efficient rollout collection.
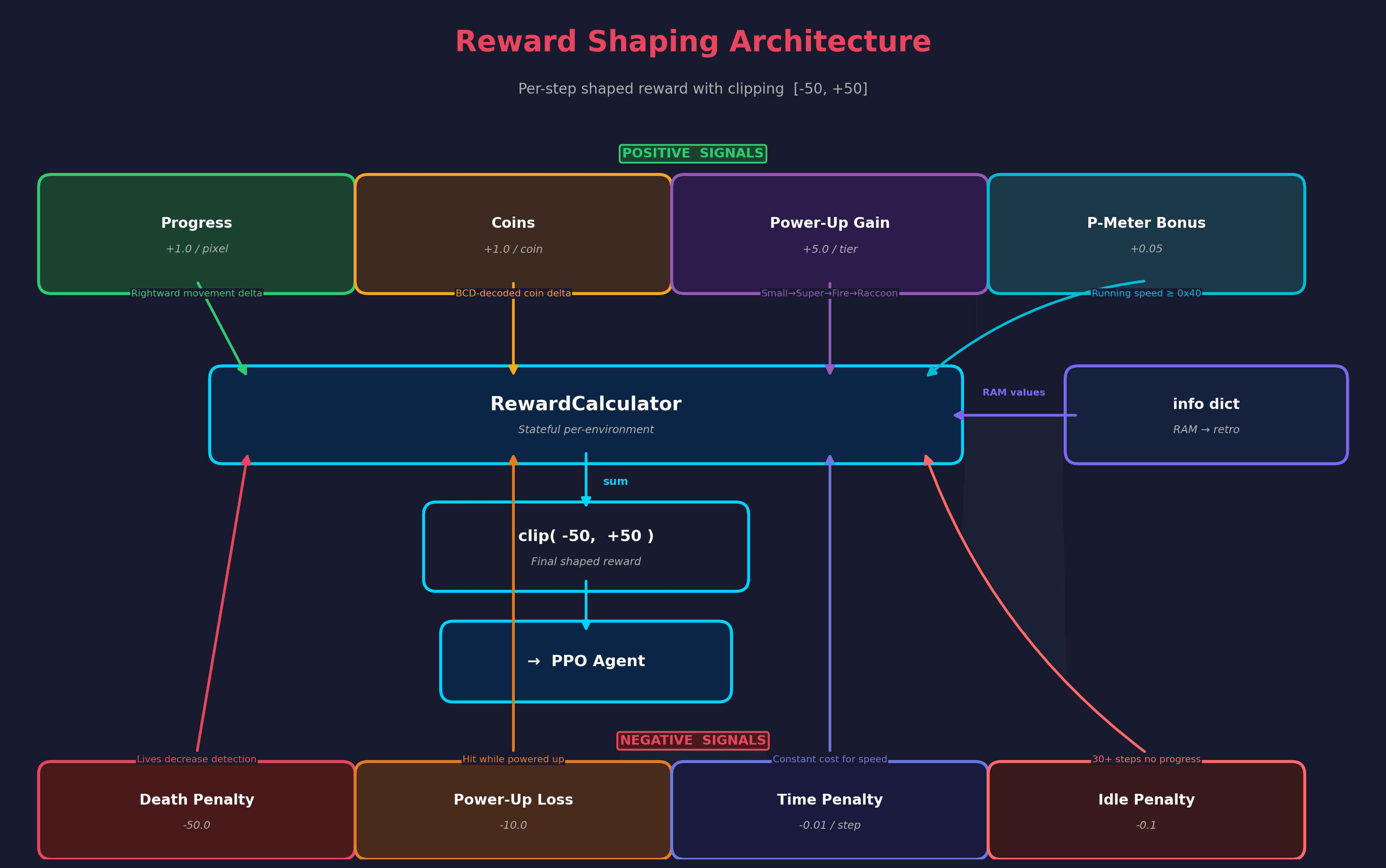
A curriculum ramps difficulty over nine phases: it starts with World 1-1 and unlocks more worlds as mean-reward thresholds are met. A custom reward calculator shapes signals around rightward progress, power-up collection, and death penalties.
Why it's a good showcase
Hits the core RL fundamentals — environment design, reward engineering, policy optimization, and curriculum learning — in a problem everyone instantly understands.
The curriculum mirrors real-world training strategy for hard tasks: start simple, scale difficulty as the model improves.
Highly visual results — watching the agent go from random flailing to purposeful play makes for a compelling demo.
Where it stands
Actively in development. The training pipeline, curriculum system, and reward shaping are all working; the current focus is tuning hyperparameters and extending training runs toward consistent level completions across worlds.
Key features
- PPO (Proximal Policy Optimization) via Stable Baselines3
- CnnPolicy on raw pixels (84×84 grayscale, 4-frame stack)
- Curriculum learning across 9 progressive phases and all worlds
- Custom reward shaping (rightward progress, power-ups, deaths)
- SubprocVecEnv for parallel environment rollouts
- NES emulation via gym-retro
A closer look
thanks for reading ✦
Like what you see?
I’m always happy to talk through the details — or about a problem you’re trying to solve.